Project 1
Spring 2024
Due: F 2/2 Sa 3/3 @ 5 PM ET
10 points
For this project, we're going to France. Formidable! It will be Uh-MAZE-ing. You will implement state-space search routines for finding paths in mazes and weighted graphs.
For this and subsequent projects, you must implement your program using Java 11. Your code must be well-structured and well-organized and follow object-oriented design principles.
For this and subsequent projects, you must implement your program using only the standard libraries the language provides. If you want to use external libraries or something non-standard, check with me first.
You can use any platform for development, but for this and subsequent projects, the source must compile on the command line using the following command within the directory containing your source:
$ javac *.javaThis is the command that Autolab will use to build your project. Do not use packages.
I put some starter code on “cs-class” (i.e., class-1.cs.georgetown.edu). To get started, log on to cs-class and copy over the following zip file:
cs-class-1% cd cs-class-1% cp ~maloofm/cosc3450/p1.zip ./ cs-class-1% unzip p1.zipIn the p1 directory, you will find a Makefile and class definitions for Action, State, Problem, and MarksMain. The use of the Makefile is optional. I provided it for your convenience and to illustrate the application logic for the project.
Your implementation must work for any state-space search problem, so you will need to derive classes for finding paths in France and in mazes from Action, State, and Problem. The code in Main should help you understand these classes and the other classes and methods you will need to implement. Do not change the names of the classes or methods that I have specified in this assignment. Additionally, I will evaluate your implementation on a search problems that you have not encountered before.
Implement
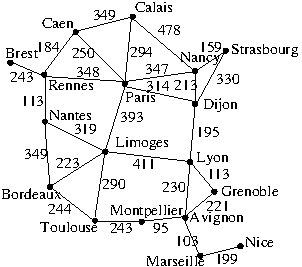
Derive a class from Problem and encode the following weighted graph:
Use the following latitudes and longitudes for the cities to write a function that returns the estimated distance between two cities.
Nice 43:42:12N 7:15:59E Toulouse 43:36:16N 1:26:38E Limoges 45:50:07N 1:15:45E Nancy 48:41:37N 6:11:05E Dijon 47:19:00N 5:01:00E Strasbourg 48:35:00N 7:45:00E Caen 49:11:0N 0:22:00W Lyon 45:46:00N 4:50:00E Rennes 48:06:53N 1:40:46W Montpellier 43:36:43N 3:52:38E Grenoble 45:10:18N 5:43:21E Avignon 43:57:00N 4:49:00E Nantes 47:13:5N 1:33:10W Paris 48:51:24N 2:21:03E Marseille 43:17:47N 5:22:12E Bordeaux 44:35:14N 5:08:07E Calais 50:56:53N 1:51:23E Brest 48:23:00N 4:29:00W
The file france.txt should help you save a few keystrokes, especially if you know how to program. There is also a copy of this file in p1.zip.
The Main.main that you submit should use each of the three search methods to find a path between the following initial and goal cities:
| Run | Initial State | Goal State |
| 1 | Brest | Marseille |
| 2 | Montpellier | Calais |
| 3 | Strasbourg | Bordeaux |
| 4 | Paris | Grenoble |
| 5 | Grenoble | Paris |
| 6 | Brest | Grenoble |
| 7 | Grenoble | Brest |
For each algorithm and then for each pair, your Main.main should print to the console the cost of the solution, the actions, and the counts.
Of course, when you are in Paris, it is important to be able to navigate the catacombs. For this task, implement the class Maze and the constructor Maze(String filename) that reads a maze from the specified file with the following format:
%%%%%%% % S% % %%% % % % % %% %% %G %%%% %%%%%%%Percent signs (%) represent walls, ‘S’ designates the starting or initial state, and ‘G’ designates the goal state. Note that S and G are optional parameters. The constructor should set the initial and goal states based on S and G if they are present in the file. There are four maze files in the zip file that I provided.
Regardless, the application programmer should be able to set initial and goal states by calling Problem.setInitialState or Problem.setGoalState and providing the appropriate state. To facilitate this, implement the MazeState class and the constructor MazeState(int x, int y) that sets the x-coordinate and the y-coordinate, respectively, of the state.
OpenAI's terms of use for their systems including ChatGPT stipulate that users “must own their queries.” To me, this seems like a sound guiding principle for the use of large-language models for this class. The challenge is, you and I do not own much of course material. The material in the textbook is protected by copyright. From the preface:
Copyright © 2021, 2010, 2003 by Pearson Education, Inc. or its affiliates, 221 River Street, Hoboken, NJ 07030. All Rights Reserved. Manufactured in the United States of America. This publication is protected by copyright, and permission should be obtained from the publisher prior to any prohibited reproduction, storage in a retrieval system, or transmission in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise. For information regarding permissions, request forms, and the appropriate contacts within the Pearson Education Global Rights and Permissions department, please visit www.pearsoned.com/permissions/As you can see, to transmit material from the book to a system such as ChatGPT, we would have to obtain permission prior to that use. I am fairly certain they would not grant us permission. Heck! They don't even produce an electronic version!
The algorithms in my lecture notes are based primarily on the textbook's. Consequently, they also are protected by the publisher's copyright. I have made my own modifications, but since they are minor modifications, the algorithms in my lecture notes are derivative works. It would be difficult for me to argue that they are new works. Crucially, I can not use these algorithms as queries to ChatGPT because it would violate OpenAI's terms of use, Georgetown's Acceptable Use Policy, and copyright law.
One could (try to) argue that we can submit information from the book to ChatGPT under the fair-use provision of the copyright law. In order for the fair-use provision to apply there must be a transformative use. What constitutes a transformative use is complex, and I am not a lawyer, but I am fairly certain that copying material from the textbook or my lecture notes and submitting it to ChatGPT is not a transformative use. Furthermore, OpenAI's stipulation that you “own” your queries stymies the argument that a query consisting of someone else's intellectual property is transformative. How much transformation would be required before their intellectual property becomes yours?
The textbook's authors are nice enough to distribute the algorithms for the book without a fee, but these algorithms are protected by copyright or by the Creative Commons Attribution 4.0 International License. While the so-called CC BY 4.0 is much less restrictive than the protections afforded by copyright law, it does not grant ownership. It is designed primarily to give credit to the originator through modifications and redistribution of the work.
Given all of this, I think the best way to proceed with using AI tools for the class assignments is to paraphrase. Rather than copying protected material such as an algorithm and then pasting it into an AI tool, you should learn how the algorithm works and then query the AI tool based on your understanding. For example, you can ask ChatGPT to generate an implementation of the A* algorithm in Java. ChatGPT and other large-language models were trained on all the algorithms and implementations that we are studying. You can use ChatGPT's implementation to help you understand the algorithm from class. You can use the algorithm from class to help you understand ChatGPT's implementation, including its possible flaws. With this understanding, you can use ChatGPT to refine its algorithm, or you can refine the implementation yourself.
Ultimately, I think you want to use your brain to devise queries based on your understanding of the material. This way the majority of the flow of information will be from ChatGPT to you and your project solution. While this may seem like a convoluted process, it should help you avoid break any rules.
Finally, as I said in class, this is new territory for me, and I am eager to learn from your experiences and perspectives. If you have other ideas for how to use AI tools for software development while navigating around the legal issues, it should make for an interesting class discussion.
In accordance with the class policies and Georgetown's Honor System, I certify that, with the exceptions of the course materials and those items noted below, I have neither given nor received any assistance on this project. Name NetID
When you are ready to submit your project, create the zip file for uploading by typing:
$ zip submit.zip Main.java (other java files) Makefile README HONORYou can also type:
$ make submit
Upload submit.zip to Autolab. You can submit to the compile check p1c five times. You can submit your assignment p1 two times. Make sure you remove all debugging output before submitting.
Copyright © 2024 Mark Maloof. All Rights Reserved. This material may not be published, broadcast, rewritten, or redistributed.